Meta's open play: Commoditisation of LLMs
In November 2022, OpenAI released ChatGPT, showing that large enough models can learn language effectively. ChatGPT is an industrialized product to which users can subscribe to. Its ease of access and its flexibility immediately sparked lots of use cases (translation, story telling, editing, …), attracted tons of news and a multibillion dollar investment in OpenAI from Microsoft.
With ChatGPT, OpenAI turned LLMs from custom-built prototypes into a ready-to-use product, on which they had almost complete monopoly. Later on, when Meta entered the market, instead of competing directly against OpenAI, they decided to use an open play to reduce OpenAI’s advantage.
This post looks back at the past few months to analyze Meta’s move, show how LLMs went from products to commodities, and guess what’s next.
# A Wardley Map about LLMs
A Wardley Map plots the user value of activities against their evolutionary status. As all maps, it’s inaccurate, but it can be useful. A Wardley Map about LLMs looks as follows:
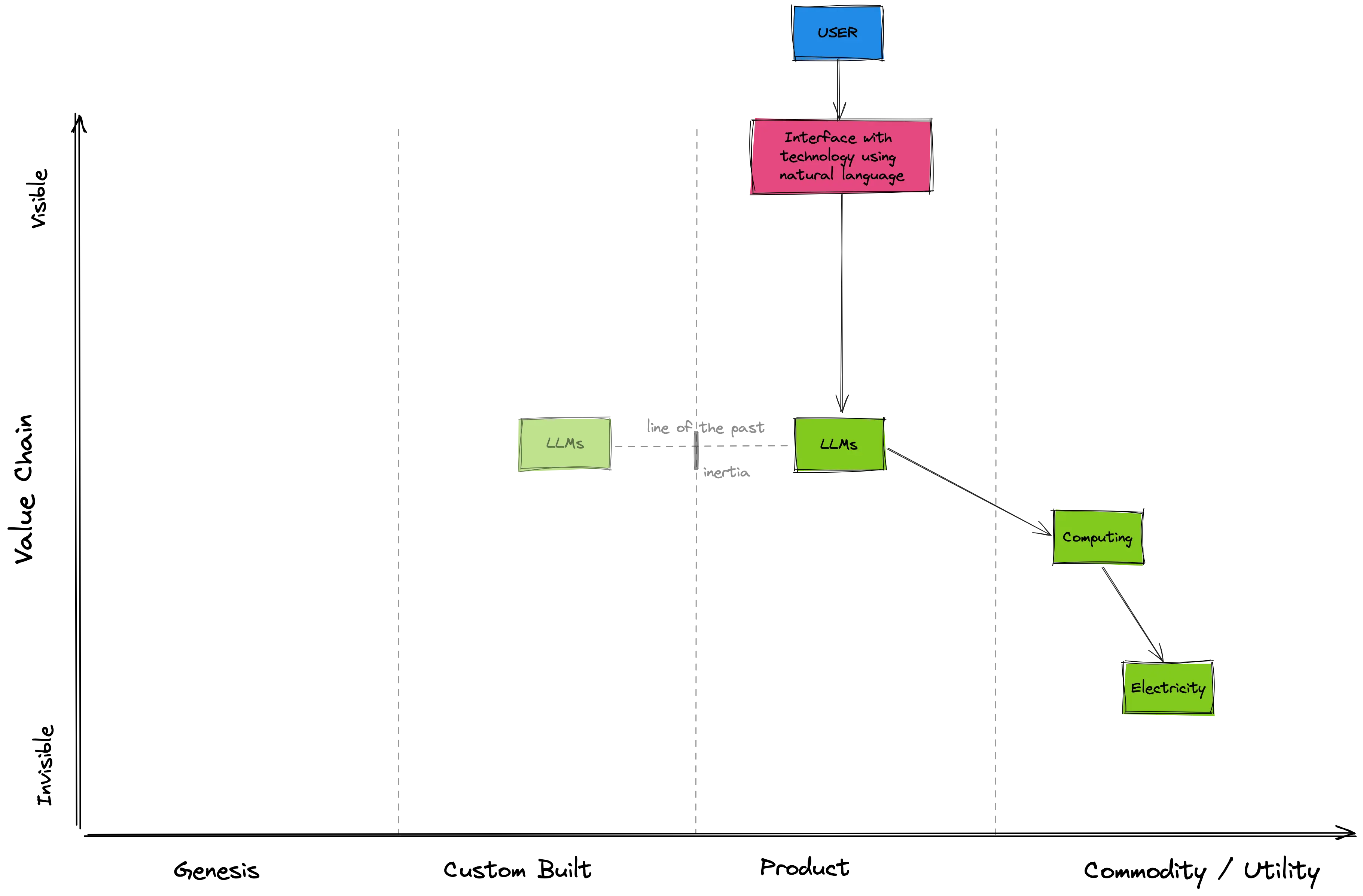
Reading it from top to bottom, we start from the user and their needs. In this case, ChatGPT understands our intentions, expressed in natural language, and serves us as a personal assistant knowledgeable in several fields.
Arrows denote relationships of “need” between the entities1. LLMs fulfill the user’s need and, for this, rank high on the value chain. In turn, LLMs need large computing power; the user might be aware that there’s computing involved in the LLMs producing an output (for instance, might assume that better computing would produce output faster), but doesn’t need to get too involved with it. Lastly, computing needs electricity (plus a ton of other needs, but we don’t need them in our map). As users, we know that computing relies on electricity, but we don’t typically think about it. That’s pretty low on the value chain.
Things get interesting when we add the evolutionary status of these activities. Electricity is the rightmost in our evolution axis (the horizontal one). That’s because it is a commodity. It’s entirely fungible to the consumer; it is standardized, and we don’t care who we get it from. We will most likely try to get it as cheaply as possible, we will easily switch from a provider to another, and we’ll be fairly surprised if things fail (e.g. blackouts).
Computing is not as evolved as electricity, but it’s almost there. The cloud enables us to deploy standardized software stacks (e.g. containers) across data centers. Switching cloud providers is painful, but can be pulled off. Data-center failure is pretty unusual and cloud providers focus more on high volume and profit optimization than on innovation.
Let’s now look at LLMs. Our map tells us of the specific point in time when ChatGPT was launched. Before (see the line of the past) LLMs were custom-built emerging technology used to prove feasibility, assess performance, and assess demand.
ChatGPT, instead, turned LLMs into products. It created a big, growing market that attracted several competitors. Stakeholders started focusing on constant improvement. Users learned to expect LLMs to be prevalent (think about personal assistants, chatbots, integration in code editors, etc.) and compared one to the other based on feature difference. The transition from custom-built to product encountered some initial inertia (e.g., due to training data, required computing, capital), but had completed.
# Meta’s open play
Maps of this kind are useful to visualize the system, reason about it, make educated guesses about the future state of things and even strategize possible movements to influence them – how to shape the map according to our plans.
In addition, history tells us that when things evolve, they do it due to competition. As activities travel across the horizontal axis, the uncertainty around them decreases – and so do profit margins from their operation. Nothing can stop evolution: if there’s competition, it will always lead to evolution. But smart players can influence its speed.
With LLMs too, that’s exactly what happened.
Soon after ChatGPT’s release, other players started to enter the LLMs market. Meta, most notably, introduced LLaMA in February 2023.
With LLaMA, Meta aced a few things – that as we’ll see will be fundamental to their play:
- LLaMA’s performance was comparable to GPT-3; and
- it was released under a permissive (but noncommercial) license, that required users to ask Meta for access. Meta could have provided it “as-a-service”2 or tried to put up other kinds of restrictions. Instead, they chose a pretty light access model.
The “ask Meta for access” model lasted for… about a couple of weeks, when someone leaked the model on 4chan and enabled open distribution.
Once leaked, the community immediately started to tinker with it by fine-tuning it, quantizing it, and so on (and creating all sort of funny licensing issues). In a matter of days, the community had taken the model, deployed it, and was now advancing it.
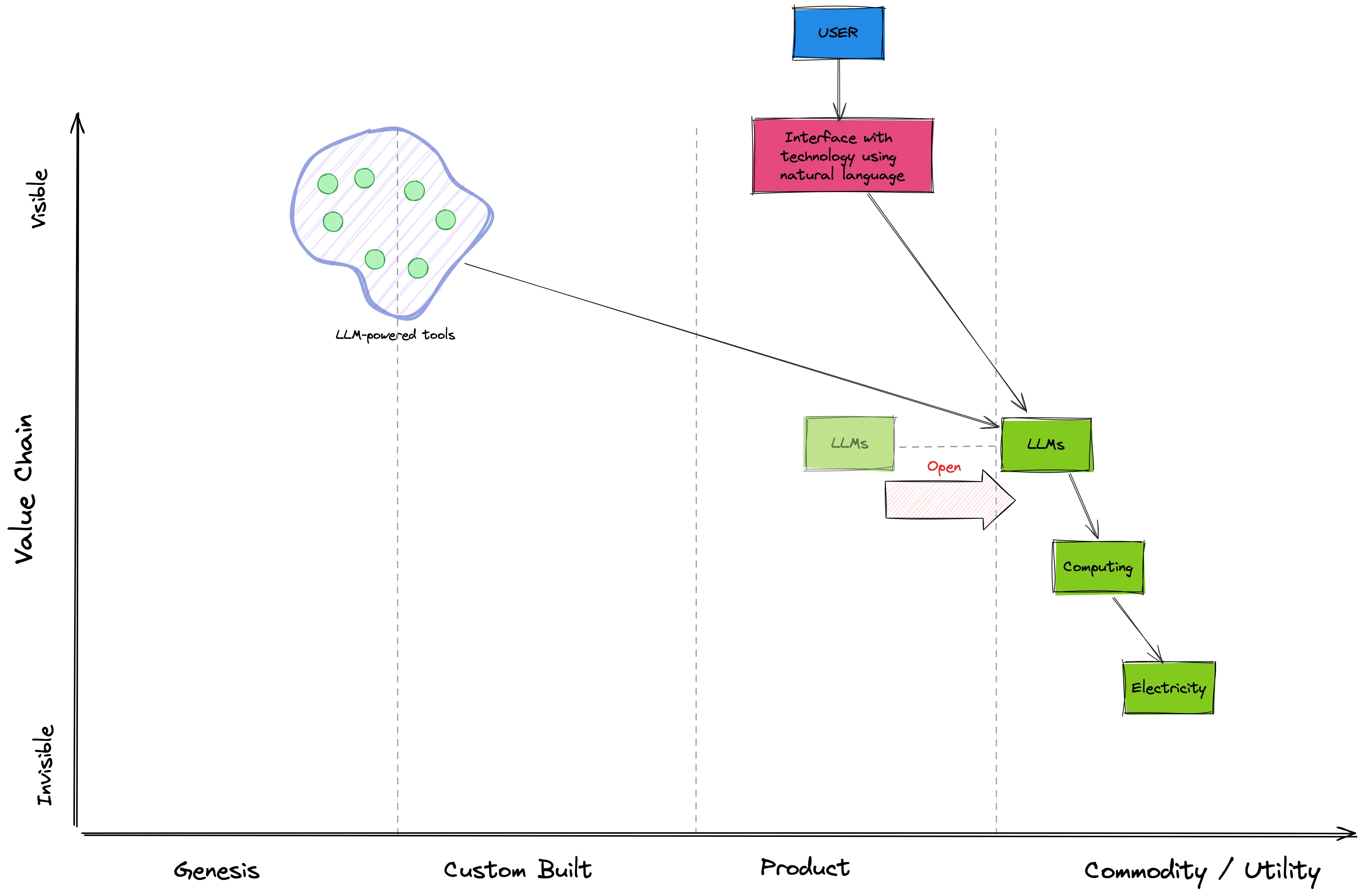
Meta’s almost-open approach was a great strategic play, because once leaked it accelerated the evolution of LLMs from product to something more similar to a commodity3. Meta itself only had to make available a model good enough to compete with ChatGPT, then the community did the rest.
Open source seemed to accelerate competition for whatever activity it was applied to.
The play and a decision to act. Chapter 5 of Wardley Maps
Both openness and performance were keys to the success of the play. Without them – for instance, with an “as-a-service” offer – the APIs would have likely been incompatible between OpenAI’s and Meta’s LLMS. The cost of switching from one to the other would have been higher and the advantages reduced. There would have been friction (another form of inertia), reducing the effectiveness of the play. Similarly, were LLaMA not comparable to ChatGPT’s performance, switching would have meant downgrading quality.
Instead, the community quickly standardized the interfaces to these models, with most tools and frameworks now exposing an OpenAI-compatible REST API schema while deploying other models. Through these standard interfaces, users can easily try experiment with different models and pick the best one according to their needs. They can fine-tune them to optimize performance and, more importantly, “self-host” them – a win for privacy too!
All this reduced OpenAI’s moat, providing alternatives to their offering – a great thing for consumers and for Meta as well. Also, as an activity becomes more industrialized (i.e., evolves), its profit margins decrease and the focus shifts on improving operational efficiency. We could speculate that is what’s going on behind the scenes at OpenAI.
For builders, industrialized LLMs also mean that very there’s little payoff in building new LLMs in-house. Commodities have clear definitions and expectations, are standard, and should be typically outsourced, so that entrepreneurs can focus their energy on building what’s valuable to (their) users. And as we’ll see, that’s exactly what is happening.
# What’s next?
The evolution of a practice/activity to a commodity (or utility) also triggers co-evolution, which at the same time: 1. Deprecates legacy practices and 2. Fosters the co-development of new practices. This happened several times already, for example with the move from on-prem infrastructure to the cloud, which led to the deprecation of most on-prem system administration practices and gave birth to DevOps.
LLMs-as-commodities are pushing us in the same direction. They gave genesis to an entirely new set of tools (and dozens of AI-based startups). Sure, there’s a lot of uncertainty about them. Some might be worth billions, others will disappear. But they are surprising and exciting, and sometimes confusing. Their market is undefined yet, unstable and will evolve over time. But there might be hidden gems being developed right now. For all these reasons, I have mapped them across genesis and custom-built evolution in the map above. That’s where we will see the innovation that will change how we do and build things. That’s also where high-risk, high-rewards opportunities live.
With their open play, Meta bought time and prevented OpenAI from cementing their monopoly for good. But OpenAI still sits on a significant advantage in terms of capital, skills, and iteration velocity. Plus, they can leverage their privileged position (as API providers) to acquire market intelligence and learn from their users (those who interact with ChatGPT, with its APIs, and even provide human feedbacks to their answers). Armed with such intel, they can get a private peek at what the market is building (remember those exciting new LLM-based tools?). With their capital, they can evolve it into a product faster than anyone else4 – cannibalizing all others in the industry.
Their moat has shrunk, but it will take a lot more for Meta and the other incumbents to have a shot at their castle.
# Addendum: from Meta’s perspective
After hitting “publish” on this, I was chatting about it with the IndieWeb community. James pointed me to Meta’s 2023 Q1 earnings call, where Eric Sheridan from Goldman Sachs asks Zuckerberg to follow-up about open-source with respect to AI.
From page 9 of the transcript:
For us, it’s way better if the industry standardizes on the basic tools that we’re using and therefore we can benefit from the improvements that others make and others’ use of those tools can, in some cases like Open Compute, drive down the costs of those things which make our business more efficient too.
The transcript adds perspective to Meta’s move and shows one more (positive) outcome of their open play. Not only weakening OpenAI’s position, but enabling outsiders to improve the technology that Meta uses internally and providing a pool of talent, already trained in the relevant contexts, for them to hire.
Do you have any feedback or comment? Please get in touch, I’d love to hear them.
Meanwhile, thank you for reading! ‘til next time! 👋
# Footnotes
-
In systems term, boxes represent stock (of capital, e.g. data, knowledge, financial assets, and so on) while arrows represent flow of capital between stocks. ↩
-
As Google later did, with
BardGemini. ↩ -
We are almost there, but not yet. Failure in commodities/utilities should be unlikely, but it’s not that unusual for ChatGPT to be unavailable for brief times. ↩
-
This pattern is called “sensing engine” or “innovate - leverage - commoditise (ILC)”. For the systems people reading, it creates a reinforcing feedback loop. ↩